قالب های فارسی وردپرس 2
این وبلاگ جهت دسترسی آسان شما عزیزان به قالب های برتر وردپرس به صورت فارسی تدوین و راه اندازی شده است.قالب های فارسی وردپرس 2
این وبلاگ جهت دسترسی آسان شما عزیزان به قالب های برتر وردپرس به صورت فارسی تدوین و راه اندازی شده است.رایانش مرزی یا Edge Computing چیست
در این مقاله تصمیم داریم با مفهومی به نام رایانش مرزی یا Edge Computing بیشتر آشنا شویم.
ممکن است شما هم مقالات یا مطالبی پیرامون رایانش مرزی شنیده باشید. واژههایی مثل Edge یا کلاد (ابر) از واژههای مصطلح هستند. اما وقتی وارد دنیای فناوری میشوند یا اینکه پدیدهی جدیدی با نام آنها در دنیای فناوری پدیدار میشود، باید بهدنبال معانی جدیدی برای آنها باشیم. اما رایانش مرزی یا اج چیست؟
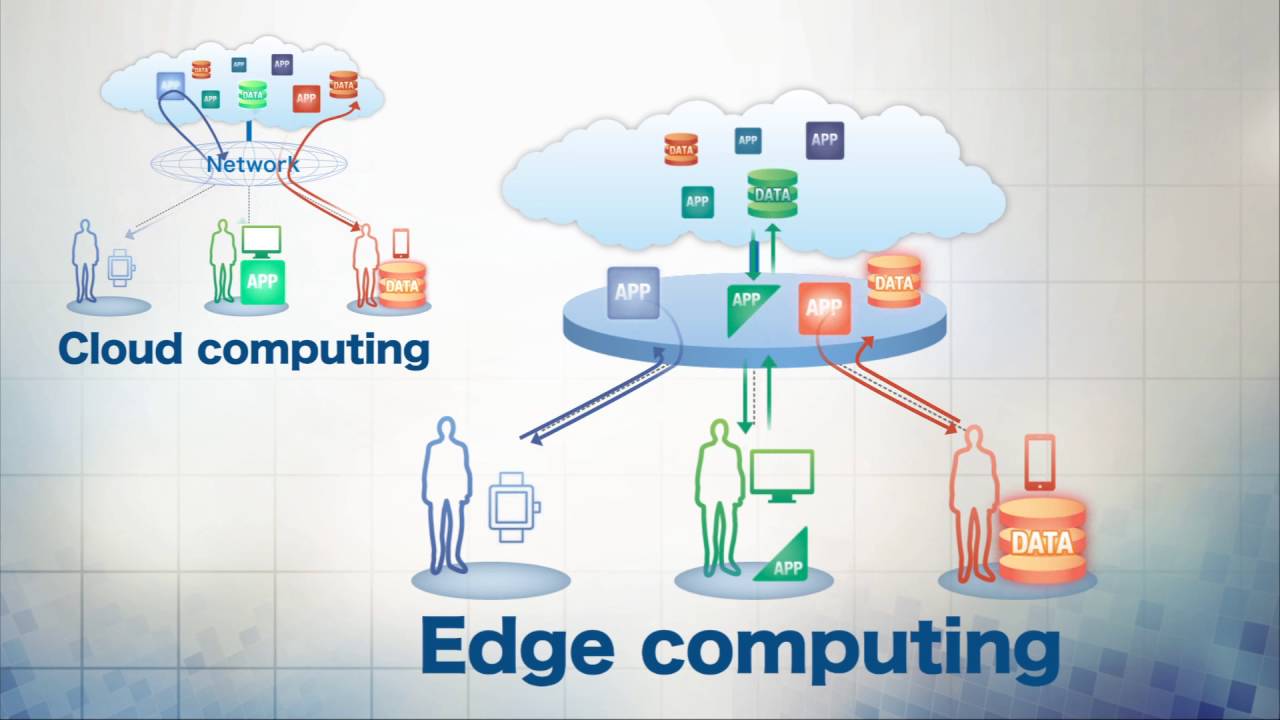
رایانش مرزی چیست؟
در ابتدا، تنها یک کامپیوتر بزرگ وجود داشت. بعد از آن و در دورهی یونیکس ما نحوهی متصل شدن به آن کامپیوتر را با استفاده از پایانهها یاد گرفتیم. سپس کامپیوترهای شخصی وارد کار شدند و مردم عادی با ورود آنها برای اولین بار صاحب سختافزارهایی برای خودشان شدند.
اکنون درسال ۲۰۱۸ وارد عصر رایانش ابری شدهایم. بسیاری از ما هنوز کامپیوترهای شخصی داریم، ولی اکثرا از آنها برای دسترسی به سرویسهای متمرکزی مثل دراپباکس، جیمیل، آفیس ۳۶۵ و اسلَک استفاده میکنیم. همچنین دستگاههایی مثل آمازون اکو، گوگل کرومکست و اپل TV دارای محتویات و هوش ابری هستند (برعکس دستگاه DVD در مجموعهی تلویزیونی خانهی کوچک یا نسخه CD دانشنامه انکارتا که کاربران در دورهی کامپیوتر شخصی از آنها لذت میبردند.
رایانش ابری غیر از متمرکز بودن، جنبههای جالب دیگری هم دارد. درصد زیادی از شرکتهای جهان اکنون متکی به زیرساخت، میزبانی، یادگیری ماشینی و قدرت پردازش ارائهدهندگان خدمات ابری مثل آمازون، مایکروسافت، گوگل و IBM هستند.
آمازون بهعنوان بزرگترین ارائهدهندهی خدمات ابری عمومی (منظور از عمومی، نقطهی مقابل خصوصی موجود در شرکتهایی مثل اپل، فیسبوک و دراپباکس است) ۴۷ درصد بازار را در سال ۲۰۱۷ به خود اختصاص داده بود.
پیدایش رایانش ابری باید ذهن ما را به این سمت ببرد که شرکتهای بزرگ میدانند دیگر جای رشد چندانی در فضای ابری باقی نمانده است. تقریبا همهی مواردی که میتوان آنها را متمرکز کرد، متمرکز شدهاند. پس اکثر فرصتهای جدید برای ابر، وارد رایانش ابری شده است؛ اما اج چیست؟
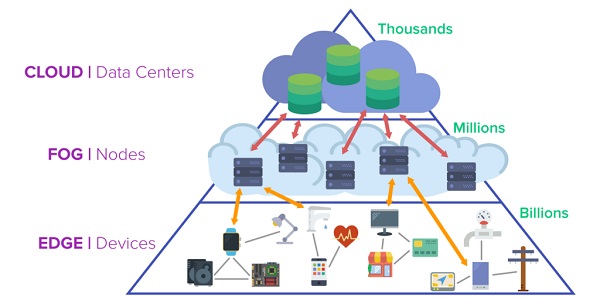
لغت اج در این متن بهمعنای توزیع جغرافیایی لفظی است. رایانش اج یا مرزی، بهجای رایانش ابری که در حدود بیش از ۱۰ مرکز داده انجام میشود، در خود منبع داده انجام میشود. البته چنین امری بهمعنای پایان راه رایانش ابری نیست، بلکه بدین معناست که خود شما بهعنوان کاربر هم بهگونهای نقش ابر را بازی خواهید کرد. اکنون از بحث لغوی اج خارج میشویم و در عمل رایانش اج را بررسی میکنیم.
تأخیر
یکی از مزایای رایانش اج سرعت فوقالعادهی آن است. در حال حاضر اگر کامپیوتر A بخواهد با کامپیوتر B در آن سوی دنیا ارتباط برقرار کند، کاربر با تأخیر مواجه خواهد شد. لحاظات کوتاهی که بعد از کلیک کردن روی لینک، مرورگر صفحه را باز میکند، بهدلیل همین بحث سرعت است. بازیهای ویدیویی چندنفره برای کاهش تأخیر بین کامپیوتر شما و دوستتان موقع شلیک به یکدیگر، از تکنیکهای خاصی استفاده میکنند.
دستیاران صوتی معمولا باید درخواستهای کاربر را در فضای ابری بررسی کنند و این امر رفت و برگشتی میتواند زمانبر باشد. اکوی آمازون باید سخنان کاربر را پردازش کند، آن را فشرده کرده و به فضای ابری بفرستد؛ و دادههای ارسالی در آنجا هم باید توسط یک رابطه برنامهنویسی کاربردی مورد بررسی قرار بگیرد تا در نهایت مورد سادهای مثل وضعیت آبوهوا را در اختیار کاربر درخواستکننده قرار دهد. درنهایت جواب سوال کاربر از طریق اکو به او منتقل میشود و مثلا وی متوجه میشود که آبوهوای امروز فلان دماها را دربر خواهد داشت و او باید برای مثال لباس گرم بپوشد.
از همین رو، این ایده که که آمازون روی تراشههای خودش برای الکسا کار کند، میتواند کاملا معقول باشد. هرچه پردازش آمازون روی دستگاه اکوی محلی کاربران بیشتر شود، اتکا و وابستگی اکو به فضای ابری کمتر میشود. بنابراین آنها جوابهای خود را سریعتر دریافت خواهند کرد، هزینهی سرورهای آمازون کاهش خواهد یافت و اگر اقدامات لازم انجام شود، حریم خصوصی کاربران نیز تقویت خواهد شد (البته اگر آمازون هم برای این موضوع تلاش کند).
حریم خصوصی و امنیت
رایانش اج مزایایی برای حریم خصوصی دارد، ولی تضمینی در آنها نیست.
شاید فکر کردن به حریم خصوصی در ابتدا کمی عجیب باشد؛ ولی قابلیتهای امنیتی آیفون میتواند نمونهی خوب و قابل قبولی از رایانش اج باشد. اپل تنها با رمزگذاری و مرتب کردن اطلاعات بیومتریک یا زیستسنجی دستگاههای خود، نگرانیهای مربوطبه امنیت و حریم خصوصی ابر متمرکز در دستگاههای کاربرانش در دنیا را حل میکند.
اما دلیل دیگری که ما احساس متفاوتی نسبت به رایانش مرزی داریم، توزیع کار پردازش است. تعیین کار پردازش بهصورت مرکزی مدیریت میشود. یک کاربر مجبور نبود برای ایمن نگه داشتن آیفون خود، سختافزار و نرمافزار و بهترین اقدامات امنیتی را ترکیب کند.
بحث مدیریتی رایانش اج، برای امنیت بسیار مهم هستند. مثلا مدیریت ضعیف اینترنت اشیاآسیبهای زیادی به مصرفکنندگان وارد کرده است.
SwiftOnSecurity در ۱۷ اکتبر سال ۲۰۱۷ چنین اعلام کرده بود:
لوازم الکتریکی مصرفکنندگان، بهمنزلهی جعبههایی پلاستیکی همراه با یک توزیع لینکوس داخلی رها شده هستند.
بههمین دلیل، مایکروسافت در حال حاضر روی آژور اسفر کار میکند که شامل نسخهای از سیستم عامل لینوکس، یک میکروکنترلر و یک سرویس ابری کار میکند. ایدهی پشت کار مایکروسافت این است که دستگاه توستر شما هم باید بهاندازهی ایکسباکس آپدیت و مدیریت شود تا شانس هک شدن آن پایین بیاید.
نمیدانیم که صنعت دنیا از راه حل ویژهی مایکروسافت برای مشکل امنیتی اینترنت اشیا استقبال خواهد کرد یا خیر؛ ولی بهنظر اکثر سختافزارهایی که چند سال پیش خریدهایم، آپدیت خواهند شد و کار مدیریت آنها بهصورت مرکزی انجام خواهد شد. در غیر این صورت، دستگاه برشتهکن و ماشین ظرفشویی به یک باتنت تبدیل میشود و زندگی شما را نابود خواهد کرد.
اگر به گفتههای فوق شک دارید؛ نگاهی به موفقیت گوگل، مایکروسافت و موزیلا در انتقال مرورگرهایشان به یک مدل همیشهسبز داشته باشید.
به این مورد فکر کنید: شما شاید بتوانید نسخهی کنونی ویندوز خود را بهراحتی با دوستان خود در میان بگذارید؛ ولی آیا نسخهی دقیق کرومی را که استفاده میکنید میدانید؟ پردازش مرزی بیشتر مانند کروم خواهد بود تا ویندوز.
پهنای باند
مشکل امنیت اینترنت اشیا تنها مورد حلشده توسط رایانش مرزی نیست. نمونهی دیگری که رایانش مرزی به آن کمک زیادی خواهد کرد، پهنای باند است. رایانش مرزی پهنای باند زیادی را حفظ میکند.
بهعنوان مثال اگر یک دوربین امنیتی بخرید، احتمالا خواهید توانست تمامی فیلمهای آن را به فضای ابری انتقال دهید. حال اگر چند دوربین امنیتی بخرید، با مشکل پهنای باند مواجه خواهید شد. اگر دوربینها بهاندازهای هوشمند باشند که تنها فیلمهای مهم را ذخیره کنند و قسمتهای غیر ضروری را پاک کنند، در پهنای باند مصرفی کاربران صرفهجویی خواهد شد.
تقریبا هر وسیلهای که با مشکل تأخیر مواجه باشد با مشکل پهنای باند هم مواجه است. بهنظر میرسد تمرکز اصلی اپل و گوگل در حال حاضر روی اجرای هوش مصنوعی روی دستگاه کاربر بهجای تمامی دستگاههای ابری است.
گوگل روی همخوانی وبسایتها با سیستم اج کار میکند. برنامههای وب پیشرفته (PWA) دارای قابلیت آفلاین هستند؛ یعنی شما میتوانید وبسایتی را بدون نیاز به اینترنت در گوشی خود باز کنید، کارهایی روی آن انجام دهید، تغییرات را ذخیره کنید و هرگاه که راحت بودید با فضای ابری تطبیقشان دهید.
گوگل همچنین در ترکیب قابلیتهای هوش مصنوعی محلی برای حفظ امنیت و ذخیرهی پهنای باند باهوشتر شده است. بهعنوان مثال، گوگل کلیپس بهطور پیشفرض تمامی دادههای محلی کاربر را نگه میدارد و هوش مصنوعی خودش را بهصورت محلی وارد کار میکند. البته گوگلکلیپس در ثبت لحظات خوب زندگی فرد زیاد خوب عمل نمیکند؛ ولی جوهرهی اصلی آن را رایانش ابری تشکیل داده است.
مهمتر از همه
خودروهای خودران احتمالا نمونهی کاملی از رایانش اج هستند. شما بهدلیل تأخیر، حریم خصوصی و پهنای باند نمیتوانید تمامی اطلاعات ثبت شده توسط حسگرهای خودروهای خودران را در اختیار قدرت محاسباتی و تصمیمگیر فضای ابری قرار داده و منتظر واکنش آن بمانید. سفر با چنین تأخیری خطرناک است و حتی اگر شدنی باشد، شبکهی سلولی آنقدر تغییر میکند که نمیتوان روی آن برای چنین کاری حساب باز کرد.
ماشینها مسئولیت کاربر را به نرمافزار درون خود منتقل کردهاند. یک ماشین بدون سرنشین تقریبا باید بهصورت مرکزی مدیریت شود و از سازنده خود بهصورت اتوماتیک آپدیت دریافت کند. ماشین همچنین باید دادههای پردازششده را به ابر برگرداند تا الگوریتم را بهبود بخشد. سناریوی تاریکی که برای باتشدن دستگاه توستر و ماشین ظرفشویی وجود داشت برای ماشین بدون سرنشین هم وجود دارد.
درعوض چه را از دست خواهیم داد؟
برخی ترسها یا شائبههای ذهنی هم درمورد رایانش مرزی وجود دارد؛ اما هنوز ما در آن حدی پیش نرفتهایم که بتوانیم این شائبهها را بهطور دقیق و مستدل شرح دهیم. شاید بخشی از این ترسهای ذهنی کاملا بیاساس باشند.
اما یک تصویر غالب و ترسناک در حال حاضر هم وجود دارد: شرکتهایی که آن را به بهترین شکل انجام میدهند، کنترل بیشتری روی زندگی ما نسبت به زمان حال خواهند داشت.
وقتی دستگاههای داخل خانه و گاراژ کاربری توسط گوگل، آمازون، مایکروسافت و اپل مدیریت شوند، شما نباید نگران امنیت باشید. همچنین نباید نگران آپدیت، عملکرد یا قابلیتهای آنها باشید. تنها بایستی از امکاناتی که در اختیارتان قرار میگیرد، بهترین استفاده را ببرید.
کاربر هنگام بیدار شدن از خواب در اوقات صبح، از دستیار سیری، کورتانا یا الکسا درمورد دستگاه توستر، ماشین ظرفشویی، خودرو و تلفن خود سوال میپرسد. شما در دوران کامپیوتر شخصی، میتوانستید نرمافزار نصب کنید، ولی در دوره اج تنها از آنها استفاده خواهید کرد.
فیسبوک اجازه دسترسی به اطلاعات خصوصی کاربران را به شرکتهای مطرح داده است
فیسبوک دسترسیهای ویژهای برای استفاده از دادههای کاربران را در اختیار ۶۱ شرکت و کسبوکار از جمله نایکی، اسپاتیفای، UPS و همچنین برنامهی آشنایی و ملاقاتی موسوم به Hinge قرار داده است. این دسترسیها در زمانی داده شده که کاربر، داشتن چنین دسترسیهایی را مسدود کرده بود.
غول دنیای شبکههای اجتماعی، در پاسخهای کتبی خود به کنگرهی ایالات متحده در مورد فرایندهای کاری خودشان، اعلام کرد آنها به افزونههای پرشماری، اجازهی استفاده از دادههای عمومی یا پابلیک کاربران و همچنین برخی دادههای مرتبط با دوستان آنها را دادهاند. شرکت فیسبوک در ماه آوریل سال ۲۰۱۴ دستورالعملهای سختگیرانهای را برای برنامههای شخص ثالث معرفی کرد و یک سال نیز به کسبوکارهای مرتبط برای تغییر و تطبیق خودشان با قوانین جدید فرصت داد. در این میان ۶۱ شرکتی که نامشان در آن زمان در مستندات آورده شده بود، مستثنی شده بودند و ۶۰ مورد از آنها زمان اضافهای بهمدت ۶ ماه دریافت کردند. یک برنامهی کاربردی فعال در زمینهی دسترسیها با نام Serotek هم مدتزمان تمدید هشتماههای دریافت کرد.
در میان اسامی سایر شرکتهایی که از این فرجه استفاده کرده بودند، نام شرکتهای آشنایی همچونAOL، اسنپچت، پاناسونیک، اوراکل و نیسان به چشم میخورد.
این اظهارات جدید که بهتازگی افشا شدهاند، با اظهارات قبلی غول رسانههای اجتماعی در تضاد هستند. آنها قبل از این اظهار کرده بودند که برپایهی عملکرد جدیدشان در آن سال، اجازهی چنین دسترسی دقیقی را در سال ۲۰۱۴ قطع کردهاند.
فیسبوک پس از رسوایی کمبریج آنالیتیکا تحت نظارت شدیدی بوده است. این شرکت تحت فشار قرار گرفته است تا جزئیات بیشتری درمورد شیوههای کسب و کارش را منتشر کند.
سیاست بهروزرسانیشده پیرامون برنامههای کاربردی در زمینهی دسترسی به دادهها، توسعهدهندگان را مجبور میساخت تا دلایل و توجیهاتی را درمورد جمعآوری برخی اطلاعات کاربری خاص و مشخص ارائه دهند و همچنین دربارهی موارد استفاده از این دادهها توضیحاتی ارائه کنند.
فیسبوک اعلام کرد که از ماه آوریل ۲۰۱۴ تا آوریل سال جاری میلادی، بیش از نیمی از برنامه های ارائه شده برای بررسی را تحت سیاست جدید خود رد کرده است.
در یک افشای جداگانه، این شبکهی اجتماعی اعلام کرد که امتیازات ویژهای را به ۵۲ شرکت دیگر سختافزاری و نرمافزاری برای ادغام فیسبوک و ویژگیهای فیسبوک در دستگاهها و خدمات آن شرکتها فراهم کرده است و این امتیازات ویژه، دسترسی به برخی از اطلاعات اولیهی کاربر را نیز شامل میشود.
اپل، آمازون و هواوی در میان شرکتهای برخوردار از آن امتیازات ویژه قرار داشتند؛ شرکتهایی که مجوز ساخت نسخههایی از فیسبوک در دستگاهها و محصولاتشان صادر شده است.

با این حال، فیسبوک اعلام کرد که این کار بهطور طبیعی شرکتها را فقط برای ایجاد محصولات مورد تایید فیسبوک محدود کرده است و این همکاریها توسط تیم مهندسی فیسبوک مورد تایید قرار میگرفته است و ۳۸ مورد از آن ۵۲ مورد اولیه نیز در ادامهی مسیر متوقف شدهاند. سخنگوی فیسبوک در یک نشست مطبوعاتی گفت:
هدف از این مشارکتها، ایجاد فیسبوک و قابلیتهای فیسبوک در دستگاههای شریکها و سایر محصولات بود.
افراد فقط قادر به دسترسی به این تجربهها و اطلاعات مورد نیاز برای پشتیبانی از آنها بودند. این اتفاق هنگامی رخ میداد که آنها حساب کاربری فیسبوک خود را وارد کرده و یا با حسابهای دیگر خودشان همگامسازی میکردند.
ما در ماه آوریل، بهطور عمومی اعلام کردیم که قصد متوقف ساختن این رابطهای برنامهنویسی یا APIها را داریم. ما همچنان به ایجاد تغییرات دیگری میپردازیم که اطلاعات در دسترس برای به اشتراک گذاشته شدن متعلق به کاربران را برای محافظت بهتر از حریم خصوصی آنها محدود کند.
آیم آرکیباگ، نایبرئیس بخش شراکت محصول در نوشتهای در بلاگ خود اشاره کرد که فیسبوک همواره نگاه سختگیرانهای به اطلاعاتی داشته است که برنامههای کاربردی در حین اتصال فیسبوک کاربران به آنها، میتوانند استفاده کنند. وی همچنین اظهار کرد که فیسبوک محدودیتهایی را برای حفاظت بهتر از اطلاعات کاربران اعمال کرده است.
اخبار جدید پس از آن منتشر میشود که نمایندگان پارلمان انگلیس، در رابطه با تحقیقات مجلس عوام، اتهاماتی را درمورد اخبار جعلی (fake news) به فیسبوک وارد کردند؛ مبنی بر اینکه فیسبوک تلاش میکند تا دقت نظر و ریزبینی عموم مردم را از بین ببرد.
دیمین کالینز، رئیس کمیسیون دیجیتال، فرهنگ، رسانهها و ورزش مجلس عوام، پس از انجام آخرین نامهنگاریها با شرکت فیسبوک در هفتهی گذشته، آنها را به داشتن الگوی رفتاری انحرافی متهم کرد.
مارک زاکربرگ، مدیرعامل فیسبوک، تا به حال از ارائهی شواهد مرتبط به این کمیته خودداری کرده است. او بهجای این کار، کارکن ارشد امور فنی کمپانی، یعنی مایک شروپفر را بهعنوان نمایندهی خود به پارلمان بریتانیا فرستاده بود.
بازدید سایت از تبلیغات گوگلی
از چه فاکتورهایی برای افزایش بازدید سایت از طریق تبلیغات گوگل و سئو میتوان بهرهگیری کرد؟ انتخاب پسندیده کلمه کلیدی فرقی نمیکند که شما برای افزایش بازدید سایت از تبلیغات گوگلی کاربرد میکند، یا تکنیکهای سئو! اگر نتوانید واژه کلیدی صحیح را انتخاب کنید، قطعاً موفق نخواهید بود. شما میتوانید با به کارگیری ابزاری نظیر keyword planner از بهترین عبارات جهت خلق درونمایه و تبلیغات کلیکی استفاده کنید چرا که متوجه میزان چشم وهمچشمی در هر واژه کلیدی خواهید شد. تولید محتوای مناسب باز هم فرقی نمیکنید که شما از کدام تکنیک کاربرد میکنید. باید به خاطر داشته باشید که تنها دست موزه شما برای قانع کردن کاربر، محتوایی است که در اختیارش قرار میدهید. اگر از تبلیغات گوگلی بهرهگیری میکنید، به یک صفحه فرود خود بیچارگی دارید که در طراحی آن تمام المانهای لازم در عقیده گرفته شده باشد. چرا که کاربر با کلیک روی تبلیغ شما به این صفحه هدایت شده و در همین صفحه است که به پیگیری پاسخ نیازش میگردد. بنابراین اگر نتوانید وی را توجیه کنید که چرا باید از خدمات شما استفاده کند، هزینهای که برای کلیک کاربر پرداختهاید، سوخت میشود! افزایش بازدید سایت از طریق تبلیغات گوگلی و سئو از طرف دیگر، سئو درونمایه است! این شغل به مراتب سختتر است چرا که محتوای شما بهاندازهای باید خوب باشد که تمام رقبای خویش را با تیتری مانند خود پشت سر گذارد. فلذا اگر به تعقیب افزایش بازدید گوگل رایگان از راه سئو هستید، رعایت نکات زیر را مد نظر داشته باشید : استفاده از هدلاین نای گوناگون و مناسب استفاده از توضیحات متا برای هر مطلب استفاده از تگ آلت متناسب با متن برای هر عکس ایجاد تقسیم بندی نای پسندیده و گوناگون جهت ایجاد تجربه کاربری مطلوب بهینهسازی عملکرد سایت همراهان عزیز، علاقه کسان به چشم براه ابقاء روز به روز ناچیز و کمتر میشود. خصوصاً اگر به دنبال پاسخ سؤالشان باشند. پس در میانی صدها رقیبی که شما در پهنه وب دارید، بهتر است که آنها را با سرعت بارگذاری زیر مطالب سایتتان معطل نکنید! شما باید با بهینهسازی تمام قطعه کدهایی که در طراحی سایت بهرهگیری کردهاید، سرعت سایت را به حداقل برسانید و به این ترتیب پروا کاربر را به خویش جلب کنید. اگر به تعقیب ابزاری جهت سنجش سرعت سایت هستید، میتوانید از ابزار جی تی متریکس استفاده کنید. در نهایت به این نکته پروا داشته باشید، که برای افزایش بازدید سایت از طریق تبلیغات گوگلی و سئو به یک راهبرد مدون و همیشگی دربایستن دارید. به عبارت دیگر اگر از هر کدام برای یک مدت کوتاهی کاربرد کنید، بعد از مدتی به جایگاه قبلیتان بر میگردید. بعد برای حفظ جایگاه مطلوبتان، همواره در راستای معیارهای گوگل کوشش کنید!
نابودی محتوا؛ چرا گذشته در اینترنت ناپدید شده است؟
در سال ۲۰۰۵، الکس تیو، جوانی بود که رؤیایی یکمیلیوندلاری در سر میپروراند. تیو ۲۰ ساله به این میاندیشید که چگونه میتواند از پسِ هزینههای تحصیلش برآید. او سخت نگران هزینهای بود که بهزودی سربهفلک میکشید؛ پس، تصمیم گرفت یادداشتی با این مضمون برای خود بنویسد: «چطور میلیونر شوم؟» ۲۰ دقیقه بیشتر طول نکشید که او به پاسخ پرسشش رسید.
تیو وبسایتی بهنام Million Dollar Homepage راهاندازی کرد. مدل کسبوکار این وبسایت بسیار ساده بود: در صفحهی اول وبسایت، یک میلیون پیکسل فضا برای درج آگهی وجود داشت. این فضا در قالب بستههای ۱۰۰ پیکسلی و با هزینهی تنها یک دلار در ازای هر پیکسل بهفروش میرسید. وقتی شما این پیکسلها را میخریدید، دیگر تا ابد مال شما بودند. ایده ساده بود: با فروش آخرین پیکسل از این مجموعه، تیو نیز میلیونر میشد. دستِکم این نقشهای بود که وی آن زمان در سر میپروراند.
تیو درمجموع مبلغی معادل ۵۰ یورو برای ثبت دامنه و خرید میزبانی وبسایتش صرف کرد. بدینترتیب، صفحهی اصلی میلیوندلاری در ۲۶اوت۲۰۰۵ راهاندازی شد. تبلیغکنندگان پیوسته پیکسل میخریدند و آنچه دراختیارشان قرار میگرفت، عبارت بود از لینکی از وبسایت بههمراه تصویری کوچک و یک خط نوشته که هنگام قرارگرفتن اشارهگر روی تصویر کسبوکارشان ظاهر میشد.
مقالههای مرتبط:
پس از گذشت بیش از یک ماه، بهلطف کنجکاوی مردم و البته توجه رسانهها، وبسایت سادهی تیو توانست ۲۵۰,۰۰۰ دلار درآمد کسب کند. در ژانویهی سال ۲۰۰۶، آخرین مجموعهی هزارپیکسلی از این وبسایت نیز در حراجی بهقیمت ۳۸.۱۰۰ دلار فروخته شد و بدینترتیب، تیو توانست یکمیلیون دلار درآمد بهدست آورد.
هماینک، صفحهی اصلی میلیوندلاری تقریبا ۱۵ سال بعد از تاریخ ساخت، هنوز دردسترس است. بسیاری از مشتریان این وبسایت، ازجمله روزنامهی تایمز بریتانیا و سرویسهای مسافرتی معروف و حتی پرتال آنلاین یاهو، در ازای یکبار پرداخت هزینه توانستند تمام این مدت را میزبان این وبسایت آگهی باشند. این وبسایت همچنان روزانه چندینهزار بیننده دارد. بااینحساب، باید اقرار کرد این سرمایهگذاری چندان بدی هم برای آگهیدهندگان نبوده است.

صفحهی اصلی میلیوندلاری اکنون پر از لینکهای مختلف به وبسایتهایی است که دیگر وجود خارجی ندارند
تیو که درحالحاضر مسئولیت ادارهی Calm، اپلیکیشنی با محتوای مدیتیشن و ذهنآگاهی را برعهده دارد، حقیقتا به یک میلیونر تبدیل شد. باوجوداین میراث او در سال ۲۰۰۵، امروزه به چیز دیگری تبدیل شده است: موزهای زنده از دوران اولیهی اینترنت. ۱۵ سال ممکن است زمان زیادی بهنظر نرسد؛ اما از دیدگاه اینترنت، این دوره دستِکمی از یک دورهی زمینشناسی ندارد. حدود ۴۰ درصد از پیوندها در صفحهی اصلی میلیوندلاری اکنون متعلق به وبسایتهایی هستند که دیگر وجود ندارند. با کلیک بر بسیاری از آنها نیز به دامنههایی کاملا متفاوتی هدایت خواهید شد؛ گویی مدتها پیش نشانی اینترنتی اصلی این وبسایتها به مالکان جدید فروخته شدهاند.
صفحهی اصلی میلیوندلاری نشان میدهد چگونه فروپاشی این دوران اولیه از حیات اینترنت کاملا از دیدگان ما پنهان مانده است. در دنیای آفلاین، تعطیلی روزنامهای محلی اغلب با پوشش گستردهی خبری همراه است؛ اما در دنیای آنلاین، وبسایتها اغلب در سکوت میمیرند و تنها سرنخی که میتوانید از آن ببینید، صفحهای خالی است که با کلیک روی لینک، با آن مواجه خواهید شد.
استفن داولینگ نیز یکی از افرادی بوده که حدود ۱۰ سال پیش در وبلاگ موسیقی و نیز بخش موسیقی شرکت AOL مشغولبهکار بوده است. او میگوید تاکنون صدها مطلب بررسی و اخبار موسیقی و مصاحبه با هنرمندان برای AOL نوشته است. باوجوداین در کمال شگفتی، اکنون میگوید دیگر هیچ نشانهای از پیشینهی فعالیتهای او در سراسر وب دیده نمیشود.
در آوریل۲۰۱۳، AOL بهیکباره همهی وبسایتهای موسیقی خود را تعطیل کرد و فعالیت دهها نفر از ویراستاران و صدها نویسندهی شاغل در این بخشها، پس از چندین سال متوقف شد. از تمامی آن بانک اطلاعات، تنها اندکی محتوا بههمراه تعدادی مقالات ذخیرهشده در اینترنت آرشیو (InternetArchive) بهجای ماند.
«اینترنت آرشیو» بنیادی غیرانتفاعی واقع در سانفرانسیسکو است که در اواخر دههی ۱۹۹۰، بروستر کال، مهندس کامپیوتر، آن را راهاندازی کرد. این بنیاد عضوی برجسته در میان گروهی از سازمانها در سراسر دنیا است که همگی تلاش میکنند بخشی از آخرین بقایای دههی اول حضور اینترنت پیش از ناپدیدشدن کامل آن را نجات دهند.
دم وندیهال، مدیراجرایی مؤسسهی علوم وب از دانشگاه ساوثمپتون، دربارهی دستاورد این آرشیو بهصراحت میگوید:
اگر آنها نبودند، اکنون هیچ محتوای اولیهای برای کار دراختیار نداشتیم. چنانچه بروستر کال اینترنت آرشیو را بنیانگذاری نکرده بود و بدون آنکه منتظر اخذ مجوز بماند، این اطلاعات را ذخیره نمیکرد، همهچیز را از دست داده بودیم.

AOL در سال ۲۰۱۳ وبسایتهای موسیقی خود را تعطیل کرد و نتایج سالها فعالیت در تولید محتوای دستاندرکاران ناگهان از عرصهی وب محو شد
بهگفتهی وندیهال، آرشیو و کتابخانههای ملی بهلطف وجود صنعت چاپ، همواره تجربهی حفظ کتابها و روزنامهها و نشریههای ادواری را داشتهاند. بااینحال، ظهور اینترنت و فراگیرشدن سریع آن در عرصههای گوناگون ارتباطات، حتی این نهادها را نیز غافلگیر کرده است. او میگوید:
کتابخانهی بریتانیا باید نسخهای از هر روزنامهی محلی منتشرشده را داشته باشد. وقتی روزنامهها از نسخهی چاپی به نسخهی وب تغییرشکل دادند، روند آرشیوکردن نیز بهشکل دیگری درآمد. باوجوداین، سؤال این است: این وبسایتها همچون نسخههای کاغذی میتوانند منابعی مطمئن تلقی شوند؟
البته آرشیوهای روزنامهای نیز از گزند آسیبهای احتمالی در امان نیستند. آنها نیز ممکن است با تعطیلی چاپخانهها یا حین فرایند ادغام مفقود شوند. وندیهال میگوید:
تصور میکنم بیشتر روزنامهها از آرشیوهای مختصبهخود برخوردار هستند؛ اما درصورت بایگانینشدن صحیح، ممکن است آنها نیز از بین بروند.
یکی از مشکلات بزرگ در تلاش برای بایگانی اینترنت این است که اینترنت هرگز ثابت نمیماند. هر دقیقه و هر ثانیه، پستها، ویدئوها، داستانهای خبری و دیدگاههای بیشتری به انبوه اطلاعات قبلی اضافه میشود. باوجوداینکه هزینهی ذخیرهسازی دیجیتال بهمیزان چشمگیری کاهش یافته است، بایگانیکردن تمام این اطلاعات هنوزهم هزینهی زیادی دربردارد. در اینجا، این پرسش مطرح میشود: چه کسی باید این هزینهها را متقبل شود؟ بهباور وندیهال، بسیار بیشتر از ظرفیتمان تولید کردهایم.
در کشوری مانند بریتانیا، نقش حفظ میراث دیجیتال تاحدودی به گردن کتابخانهی بریتانیا افتاده است. امروزه، این کتابخانه بایگانی وب انگلستان را نیز اداره میکند که از سال ۲۰۰۴، وبسایتها را با کسب اجازه بایگانی کرده است. بهگفتهی جیسون وبر، مدیر بخش تعاملات این آرشیو، مشکل ما بزرگتر از تصور مردم است.

امروزه، تنها مقدار اندکی از محتوای وب در دوران اولیهی پیدایش اینترنت، یعنی عصر تالارهای گفتوگو و کافههای اینترنتی، بهجای مانده است
وبر در ادامه میگوید:
مشکل فقط دسترسی به محتوای دوران اولیه نیست؛ بلکه فرایند بایگانیسازی حتی امروز هم برای بخش اعظمی از اینترنت انجام نمیگیرد.
او میافزاید:
اینترنت آرشیو اولینبار در سال ۱۹۹۶ بایگانیکردن صفحات اینترنت را شروع کرد؛ یعنی پنج سال پسازآنکه اولین وبسایتهای جهان راهاندازی شدند. هیچ اطلاعاتی از آن دوره در جایی بایگانی نشده است. حتی اولین صفحهی وب که در سال ۱۹۹۱ راهاندازی شد، امروزه دیگر وجود ندارد. صفحهای که شما اکنون روی کنسرسیوم وب جهانی مشاهده میکنید، تنها نسخهای کپیشده است که یک سال بعد تهیه شد.
در طول پنج سال اول حیات وب، بیشتر محتوای منتشرشده در بریتانیا با پسوند .ac.uk خاتمه مییافت. این نشاندهندهی حجم عمدهی مقالات علمی و آکادمیک دانشگاهیان در آن زمان بود؛ اما در سال ۱۹۹۶، وبسایتهای عمومیتر نیز پا بهعرصه گذاشتند و بهمرور تعداد وبسایتهای تجاری از وبسایتهای آکادمیک نیز پیشی گرفت.
بهعنوان نمونهای از این تلاشها، کتابخانهی بریتانیا هرساله سعی میکند در رویدادی، محتواهای منتشرشده در این کشور را بایگانی کند. وبر میگوید:
سعی میکنیم همهچیز را گردآوری کنیم؛ اما این کار را فقط یکبار در سال انجام میدهیم. فضای درنظرگرفتهشده برای اکثر وبسایتها ۵۰۰ مگابایت است که این فضا تعداد زیادی از وبسایتهای کوچکتر را بهخوبی پوشش میدهد. بااینحال با وجود چنین محدودیتی، مجبورید تنها چند ویدئو را در وبسایت بگنجانید؛ درغیر اینصورت، بهسرعت به آستانهی ظرفیت مجاز خواهید رسید.
بااینحال، وبسایتهای خبری، نظیر بیبیسینیوز، اغلب بیشاز یکمرتبه در سال بایگانی میشوند. بنابر اعلام وبر، این کتابخانه تلاش کرده تاحدممکن رویدادهای مهمتر، نظیر برگزیت و بازیهای المپیک لندن و یکصدمین سالگرد جنگ جهانی اول را کاملتر پوشش دهد. وبر میگوید:
بهعقیدهی من، سطح آگاهی عوام دربارهی میزان محتوای درحالنابودی بسیار اندک است. شتاب دنیای دیجیتال بسیار زیاد است. به تلفنهای همراه خود نگاه کنید. موارد بیشماری در آنها درحالتغییر است که ما حتی دربارهی آنها فکر هم نمیکنیم؛ اما اکنون مردم درحالآگاهشدن از حجم چیزهایی هستند که از دست رفتهاند.
بهگفتهی وبر، تنها سازمانهایی خاص مجوز جمعآوری این محتوای عظیم را دارند. بااینحال، بخش بزرگتری از این دادهها که ازلحاظ تاریخی و فرهنگی اهمیت بیشتری دارند، درون آرشیوهای شخصی مردم، مانند هارددرایوها، ذخیره شدهاند. بااینحال، بهندرت کسانی در میان ما وجود دارند که واقعا قصد داشته باشند این اطلاعات را برای آیندگانشان نگاه دارند.

آرشیوها بهخوبی از اهمیت حفظ و صیانت از روزنامهها آگاهی دارند؛ ولی سرعت آنها برای این حجم روبهرشد از محتوای آنلاین کافی نیست
معمولا تصور میکنیم تمام محتواهایی که در شبکههای اجتماعی پست میکنیم، برای همیشه در آنجا خواهند ماند؛ اما ازدسترفتن بانکی عظیم از موسیقی و عکس با قدمتی ۱۲ ساله در شبکهی اجتماعی MySpace، محبوبترین وبسایت در ایالات متحدهی آمریکا، نشان داد حتی محتوای ذخیرهشده در بزرگترین وبسایتها هم ممکن است آنچنانکه تصور میکنیم، از خطر نابودی مصون نباشند..
حتی خدمات گوگل هم از چنین آسیبهایی مصون نیست. برای مثال، گوگل پلاس، حاصل آخرین تلاش غول فناوری در دنیای شبکههای اجتماعی، چندی پیش تعطیل شد. واقعا فکر میکنید تمام کاربران گوگلپلاس از تمام عکسهایی که در این شبکه بهاشتراک گذاشته بودند، فایل پشتیبان تهیه کردند؟ وبر میگوید:
گذاشتن اطلاعات در فیسبوک بهمنزلهی بایگانیکردن آن نیست؛ زیرا روزی فرامیرسد که فیسبوک نیز وجود نخواهد داشت.
اگر هنوز دربارهی ماهیت موقت دنیای وب تردید دارید، کافی است چند دقیقه زمان خود را صرف بازدید از صفحهی اصلی میلیوندلاری کنید. این تنها چشمهای از سرعت ناپدیدشدن اطلاعات ما در دنیای آنلاین است.
ازدسترفتن اطلاعات روی دیگری هم دارد. وندیهال اشاره میکند بایگانینکردن داستانها در وبسایتهای خبری ممکن است به ایجاد نمایی گزینشی از تاریخ منجر شود؛ چراکه دولتها به بایگانیکردن اخبار و داستانهایی علاقهای ندارند که بازتابکنندهی عملکرد ضعیف آنها در دورهی مسئولیت آنها است.
جین وینترز، استاد علوم انسانی دیجیتال در دانشگاه لندن میگوید:
بهمحض تغییر در ساختار دولت یا نهادهای وابسته، برخی از وبسایتها تعطیل میشوند. برای مثال، میتوانید نگاهی به وبسایتهای انتخاباتی بیندازید که ذاتا پدیدههایی موقتی هستند.
گاهی اوقات، ازدسترفتن برخی از وبسایتها نشاندهندهی تغییرات بنیادیتری هستند؛ تغییراتی نظیر شکلگیری یا نابودی یک ملت. وینترز میگوید:
این اتفاق در یوگسلاوی افتاد. پسوند yu. در رتبهی برتر دامنههای استفادهشده در کشور یوگسلاوی قرار داشت؛ ولی وقتی این کشور سقوط کرد، عمر این دامنهها نیز بهپایان رسید.
شاید چندان جای گلایهای نباشد. تاریخ ما همواره پر از شکافهایی بوده که جای برخی از آنها (عامدانه یا غیرعامدانه) با اطلاعات نامعتبر پر شده است. در بسیاری اوقات، ما حتی از وجود این شکافهای تاریخی نیز بیخبریم. مانند حلقههای فیلمهای بهجای مانده از دوران کودکیمان، احتمالا بسیاری از آرشیوهای فعلی ما برای آیندگان چندان منسجم و واضح بهنظر نخواهند رسید؛ چهبسا تا آن زمان، بسیاری از این آرشیوها سهوا یا عمدا با اطلاعاتی جایگزین شوند که چندان به واقعیت روزگار ما نزدیک نیست.
بازتولید دروغ؛ چگونه فناوری تاریخ ما را تحریف خواهد کرد؟
اواخر بهمنماه سال گذشته بود که خلاقیت یک وبسایت تازه، توجه کاربران زیادی را به خود جلب کرد. کافی است سری به آدرس وبسایت thispersondoesnotexist.com بزنید. در نگاه اول، شما تصویر یک فرد عادی را میبینید؛ اما اگر کمی بیشتر دقت کنید، با عبارتی در گوشهی پایین تصویر مواجه میشوید که میگوید: «این تصویر با یک الگوریتم شبکهی رقابتی مولد (GAN) تولید شده است». بله، شاید هضم آن برایتان کمی دشوار باشد، ولی این چهرهها که بهطرز هولناکی واقعی بهنظر میرسند، متعلق به هیچ انسانی نیستند.



تصاویر تهیهشده از thispersondoesnotexist.com، این افراد در دنیای واقعی وجود ندارند
فیلیپ وانگ، یک مهندس نرمافزار در اوبر (Uber) است که تصمیم گرفت این وبسایت را براساس نتایج فعالیت گروهی از پژوهشگران در انویدیا پایهگذاری کند تا افکار عمومی را از یک توانایی بالقوهی فناوری در خلق تصاویر باکمک الگوریتم شبکهی رقابتی مولد آشنا کند. اینها تنها برنامههایی هستند که شامل دو شبکهی عصبی میشوند. یکی از شبکهها یک تصویر ایجاد میکند و دیگری تصمیمگیری میکند که این تصاویر تاچهاندازه واقعی هستند و درواقع، خروجی برنامهی اول را باهدف بهبود نتایج، به چالش میگیرد. هدف نهایی این فرایند، خلق تصویری است که عملا از چهرهی واقعی یک انسان غیرقابلتشخیص باشد.چهرههایی که در سایت وانگ دیده میشوند، بسیار واقعی هستند. این چهرهها میتواند متعلق به هر کسی در دنیا باشند؛ درحالیکه چهرهها متعلق به هیچ انسانی نیست.
چند روز پس از راهاندازی این سایت، OpenAI از ابزاری خارقالعاده رونمایی کرد که میتوانست با کمترین دخالت انسانی، متونی منسجم شامل چندین پاراگراف را از خود بنویسد. آنها بااقتباس از نام فناوری دیگری که میتوانست با مونتاژ تصویر چهرهی یک فرد روی چهرهی فردی دیگر، ویدئوهای جعلی تولید کند، این قابلیت تازه را دیپفیکس (deepfakes) نوشتاری نام نهادند. در توضیحات گاردین اینگونه آمده است:
این سیستم هوش مصنوعی متون چند کلمهای تا یک صفحهای را بهعنوان ورودی دریافت میکند و میتواند چندین جمله را باتوجه به پیشبینیهای خود در ادامهی آن بنویسد.
مقالههای مرتبط:
OpenAI بهعلت نگرانیهای ناشیاز سوءاستفادههای احتمالی، هنوز نسخهی کامل این فناوری را منتشر نکرده است. بااینحال، گاردین از این فناوری که با نام GPT2 شناخته میشود، برای نگارش یک داستان کامل دربارهی خود این فناوری استفاده کرده است. در مقالهی اخیر، تنها دو پاراگراف در اختیار این برنامهی رایانهای قرار گرفت تا موضوعی برای شروع نگارش داشته باشد. درادامه، برنامه توانست بهخوبی با ورودیهای ارائهشده، یک داستان کامل از آب دربیاورد که تقریبا با نسخههای نگاشتهشده توسط یک انسان تفاوت چندانی ندارد. شگفتانگیز آنکه GPT2 حتی توانست چند نقلقول ساختگی نیز از سازندگان خود تولید کند. این فناوری پیشتر هم توانسته بود درحین نگارش یک متن آزمایشی درمورد برگزیت، نقلقولهایی جعلی از رهبر حزب کارگر انگلستان تولید کند.
متون GPT2 شباهت حیرتانگیزی به نوشتههایی دارد که یک انسان نوشته است، درصورتیکه هیچ انسانی آن را ننوشته است.
اجازه دهید به ماجرایی دیگر نیز اشاره کنیم. در بهار سال گذشته، گوگل از دو فایل صوتی ضبطشده پردهبرداری کرد. در این نوارهای صوتی از فناوری تقلید صدای گوگل به نام Duplex استفاده شد تا یک مکالمهی تلفنی میان یک ماشین و یک فرد واقعی ترتیب داده شود. در اولین فایل صوتی، برنامه با یک سالن زیبایی تماس میگیرد تا یک نوبت رزورو کند. طی این مکالمه، برنامه با یک سری گزینههای ارائهشده ازسوی منشی مواجه میشود که مجبور بود از پس پاسخ به آنها برآید. در فایل صوتی دوم، برنامه تلاش میکند تا یک میز برای شام رزرو کند و زنی که مخاطب این تماس تلفنی است، میگوید که امکان رزرو میز برای تعداد کمتر از چهار نفر وجود ندارد.
این مکالمات صوتی ضبطشده شباهت غریبی بهگفتههای یک فرد واقعی را دارد. اما در واقعیت، هیچ انسانی این کلمات را بهزبان نیاورده است.

پردهبرداری گوگل از فناوری Duplex در هوش مصنوعی شگفتی دنیا را برانگیخت
اواخر سال ۱۸۷۷، توماس ادیسون درحالی که آخرین اختراع خود را بههمراه داشت، وارد دفتر ژورنالعلمی Scientific American شد. آنگونه که سردبیران این ژورنال بعدها تعریف کردند، اختراع او شامل چند قطعه فلز بود که روی یک پایهی آهنی با ابعاد ۰.۱ مترمربع قرار گرفته بودند. آن دستگاه درحقیقت، یک گرامافون بود که قادر به ضبط صدای انسان و بازپخش آن بود. سردبیران مجله علمی آمریکا بعدها نوشتند:
مهم نیست که تا چهاندازه با ماشینهای مدرن و قابلیتهای شگفتانگیز آنها آشنایی داشته باشید یا اینکه چهمیزان درکی از اصول کارکرد این دستگاههای عجیب داشته باشید، ممکن نیست درحالیکه این صداهای مکانیکی را گوش میکنید، نتوانید تشخیص دهید که حواس شما درحال فریبدادنتان هستند.
ما قبلا هم به قابلیت شگفتانگیز شنیدن صدای مردگان ازطریق این دستگاه اشاره کردهایم و هیچ شکی وجود ندارد که این قابلیتها به همان اندازه شگفتآورند که بهنظر میرسند.
درواقع، هیچ راهکار عملی برای تفکیک بشریت از فناوری او وجود ندارد. در سرتاسر تاریخ، فناوری برای بهبود و پیشرفت تجارب انسانی بهکار گرفته شده است و این فناوری در خدمت هدف مهم دیگری نیز بوده است: «فناوری در بسیاری از موارد برای محافظت از بشریت تولید شده است.» این موضوع بهویژه در مورد پیدایش فناوریهای ارتباطی (از صنعت چاپ گرفته تا گرامافون و اینترنت)، صادق بوده است. فارغازاینکه سازندگان این فناوریها هنگام خلق آنها چنین تصوری را داشتهاند یا خیر و جدا از همهی آن خدمات بیشماری که این فناوریها برای ما بهارمغان آوردهاند، باید بهخاطر آورد که این ابزارها تنها راهی برای یادآوری وجود بشریت به خود اوست؛ تا به خود یادآور شویم که ما هنوز وجود داریم.
شاید از همین جهت است که این سه پیشرفت اخیر در حوزهی هوش مصنوعی قدری خاطرمان را مشوش میکند. برخلاف آنچه تاکنون شاهد آن بودهایم، هرکدام از این دستاوردها چیزی بیشاز یک «کپی» ساده از انسانها و ارتباطات انسانی است. میتوان گفت اینها بهنوعی «بازتولید» محسوب میشوند. کمی تامل کنید، این تفاوت ظاهرا جزئی میان این دو کلمه، از اهمیت بسیار بالایی برخوردار است.

بازتولید اطلاعات جعلی، قابلیتی خطرناک است که خواهد توانست تاریخ ما را نیز دستخوش تغییر کند
توجه به همین تفاوت میان دو عبارت «کپی» و «بازتولید» میتواند به ما بفهماند که در موضوع هوش مصنوعی، دقیقا با چه پدیدهای سروکار داریم: یک کپی و نسخهی اصلی آن میتوانند بهصورت همزمان و مجزا از یکدیگر وجود داشته باشند. حتی اگر نسخهی اصلی مفقود هم شود، نسخهی کپی خود مدرکی است که ثابت میکند که قبلا یک نسخهی اصلی وجود داشته است. اما از آنسو، یک نسخهی «بازتولیدشده» در حقیقت، نوعی دستکاری در نسخهی اصلی با هدف ایجاد یک گونهی جدید است. اساسا در این فرایند، بخشی از جوانب نسخهی اصلی بهکلی ناپدید میشود . این همان موضوعی است که آنچه را در سیلیکونولی میگذرد، برایمان کمی نگرانکننده جلوه میدهد. چرا که با انجام هر بازتولید موفق از چهرهها، کلمات و اصوات انسانی، آنچه که درسکوت ناپدید میشود، خود «انسان» است.
این ابزارهای جدید در هوش مصنوعی دیگر وجودمان را به ما یادآوری نمیکنند؛ در اصل، آنها این موضوع را به ما یادآوری میکنند که شاید دیگر قرار نیست روزی وجود داشته باشیم. سال گذشته،مارتین کونز در مصاحبهای چنین گفت:
ما در قالب یک گونهی زیستی گردآورنده و یادآورنده بودهایم. ما در هر جایی آثار خود را بهجای گذاشتهایم.
کونز درقالب یک کاشیکار استرالیایی درحال ساخت یک کپسول زمان است که خود نام «پروژهی یادبود بشر» را برای آن برگزیده است. او شروع به ساختن کاشیهای سرامیکی کرده که روی آن خاطرات شخصی، اخبار جهانی، متون کتابها و مطالعات علمی با لیزر حک شده است. این کاشیها بهمنزلهی توصیفی از بشریت برای کسانی خواهد بود که شاید در آیندهای دوردست در یک غار نمک میراث ما را بیابند.
این پروژه بهسرعت توسعه یافته است. در حال حاضر، کونز سه دسته از مطالب را چاپ میکند:سرمقالات که شامل مجموعهای از سرخط اخبار جراید جهان از تمامی دیدگاههای سیاسی و جغرافیایی هستند؛ مطالب سازمانی که شامل مقالات علمی، رسالهها، پروژههای هنری و موسیقیهای پرطرفدار و حتی محل سایتهای انباشت زبالههای هستهای است؛ و درنهایت آیتمهای شخصی.
در حال حاضر، او بیش از ۵۰۰ کتیبه دراختیار دارد که بامشارکت افرادی از چندین و چند کشور تهیه شده است؛ این افراد، مطالب مورد نظر خود را ازطریق ایمیل برای او ارسال میکنند تا روی یک کتیبه چاپ شوند. این مطالب شامل امور روزمره، نامههای عاشقانه، مقالات روزنامه، رسالهها، متون وبسیاری از چیزهایی میشود که برایمان اهمیت دارد.
یکی از انگیزههای کونز در حفظ این خاطرات انسانی، از نگرانیهای او درمورد عدم امکان ذخیرهسازی آنها در جاهای دیگر ناشی میشود. کونز میگوید:
دیر یا زود بنابر مسائل اقتصادی یا اکولوژیکی ما مجبور به پاککردن اطلاعات خود خواهیم شد. این پاکسازی بهصورت سازماندهیشده انجام نخواهد شد و قرار نیست خود انتخاب کنیم چه اطلاعاتی باید باقی بماند (و چه اطلاعاتی پاک شود).
ازاینرو پروژهی یادبود بشر برای آن بنیان نهاده شده تا شاید روزی که دیگر نشانی از وجود ما در قرن بیستویکم نبود، نوادگان ما بتوانند همچنان ما را به خاطر آورند.

کتیبههای پروژهی یادبود بشر قرار است یکی از آخرین میراثهای بشر برای آیندگان دوردست باشد
یک «پاکسازی بزرگ» میتواند بدین معنا باشد که اطلاعات ما برای همیشه نابود شوند، اما هنوز سرورهای ما وجود داشته باشند و دوباره بتوانند با دادههایی تازه پر شوند. حال با درنظرگرفتن این سه پیشرفت اخیر در هوش مصنوعی باید این پرسش را از خود داشته باشیم: درصورت وقوع چنین حادثهای این فضاهای خالی قرار است با چه اطلاعاتی پُر شوند؟
این ممکن است یک اشتباه بزرگ باشد که تصور کنیم درصورت نابودی اطلاعات مربوطبه زندگی نسل ما، جای خالی آنها دوباره با همان حقایق پُر خواهد شد. در عوض، ممکن است یک اتفاق عجیب رخ دهد: همانطور که هوش مصنوعی به تکامل خود ادامه میدهد و الگوریتمهای آن بهینه میشوند، ممکن است بهناگاه با جهانی مواجه شویم که در آن اطلاعات مفقودشده با اطلاعاتی جایگزین شوند که توسط انسان تولید نشدهاند. این اطلاعات ممکن است تنها چیزی شبیهبه اطلاعات بشری باشند؛ اطلاعاتی ضبطشده که تنها محصول ارتباط میان لایههای یک الگوریتم پیچیده در حلقهای بیپایان باشند.
تصور این منظره هم هم هولناک است.
یک برنامهی رایانهای یک تماس تلفنی برقرار میکند؛ برنامهای دیگر بدان پاسخ میدهد. یک الگوریتم یک داستان خبری مینویسد؛ الگوریتمی دیگر براساس آن یک رمان مینگارد. یک الگوریتم یک چهرهی انسانی تولید میکند؛ یک ربات از این تصویر برای ایجاد یک پروفایل در شبکههای اجتماعی استفاده میکند و شروع به تعامل با کسانی میکند که خود آنها نیز ممکن است محصول یک الگوریتم دیگر باشند. بدینترتیب با حلقهای بیپایان از الگوریتمها مواجه خواهیم شد که هریک روی دیگری سوار شده است.
مدتها است که ترس ما از هوش مصنوعی از این گمان ناشی میشود که نکند روزی ما بهصورت فیزیکی با یک کامپیوتر ادغام شویم و تبدیل به یک گونهی سایبورگ شویم یا اصلا بدتر از آن روزی با فرارسیدن تکینگی فناوری بهبردگی یک ابرهوش درآییم. اما واقعیت این است که امکان رخداد حوادث دیگری نیز میرود. ممکن است روزی با آیندهای روبهرو شویم که واقعیت فیزیکی ما دستنخورده باقی بماند؛ اما مجموعا نتوانیم احساسات و افکار واقعی خود را بهخاطر آوریم؛ یعنی همان چیزهایی که از ما، انسان ساختهبودند. از آنجاکه در آن روزها سرورهای ما همچنان با ارتباطاتی «بازتولیدشونده»، به رشد سرطانگونهی خود ادامه میدهند، ما بهنوعی گرفتار بنبستی از انزوا خواهیم شد و انسانیت ما برای همیشه روی لوحهایی از سرامیک در اعماق یک غار کوهستانی مدفون خواهد شد.